Uncanny resemblance: thoughts on my ongoing transition from tech to bio
September 2025
I recently left my job as a software engineer at Retool to do a 6-month research scientist fellowship at the biomedical research organization Arc Institute. Considering that my job at Retool—a B2B SaaS company—was to build React frontends and agents with OpenAI/Anthropic APIs, people are understandably confused when I tell them that I've taken a pivot into biology. To them, biology and computer science seem so fundamentally different that this transition seems inconceivable.
I think this is a common misconception though—that biology and computer science are fundamentally different—and I want to spend the rest of this piece attempting to convince you otherwise.
The last time I formally studied biology was back in 9th grade; so after leaving Retool, the natural thing to do was to pick up a textbook on cellular biology and start reading.
Reading this textbook felt like deja vu—and not due to my memories studying intro biology as a 14-year-old.
Remarkably, the processes of the cell had such an uncanny, yet beautiful similarity to many of the foundations of software systems I had previously studied and worked with; in fact, some of the hallmarks of the cell are so artfully conceived that it’s hard to imagine that evolution built them rather than some genius engineer.
I’d like to walk you through some of these cellular properties/processes and their analogs in engineering.
To start, the cell operates as an information system, demanding similar levels of fault tolerance, security, and redundancy as a production SQL database, a high-performance computing cluster, or a digital communication protocol. The core of this cellular information system is DNA—the ground-truth molecule of heredity. DNA is a simple code consisting of four base pairs (or enums if you’re a software engineer): A, T, C, and G.
Given how fundamental DNA is, it's critical that it doesn't lose any data when it replicates. Naturally—that is, without any cellular protection mechanisms—the protein responsible for copying DNA (DNA polymerase) makes one mistake for every 105 base pairs. Considering that our entire genome is 3.2 × 109 base pairs and DNA replication happens all the time, that error rate is actually quite significant. Thankfully, our cellular information system has built-in self-correction that prevents fatal DNA corruption—and that self-correction is due to a simple, yet powerful redundancy mechanism that we perhaps take for granted: DNA's double-strandedness.
Whenever DNA polymerase makes a mistake in copying base pairs on one strand, it’s able to look at the other strand to correct itself through mechanisms such as proofreading, mismatch repair, and homologous recombination. With these correction mechanisms, the error rate goes down to 1 in 109—much better. Fundamentally, all the information necessary for our biological function is carried in one strand; the other strand is just a mirror image kept for fault tolerance.
I found this remarkably similar to RAID 1—a fault tolerance scheme used in many databases and compute clusters. The core principle of RAID 1 is similar—if not the same—as DNA’s double-strandedness: data is carried on two disks, each a mirror image of the other. If one disk fails, the RAID system can copy the data from the other disk.
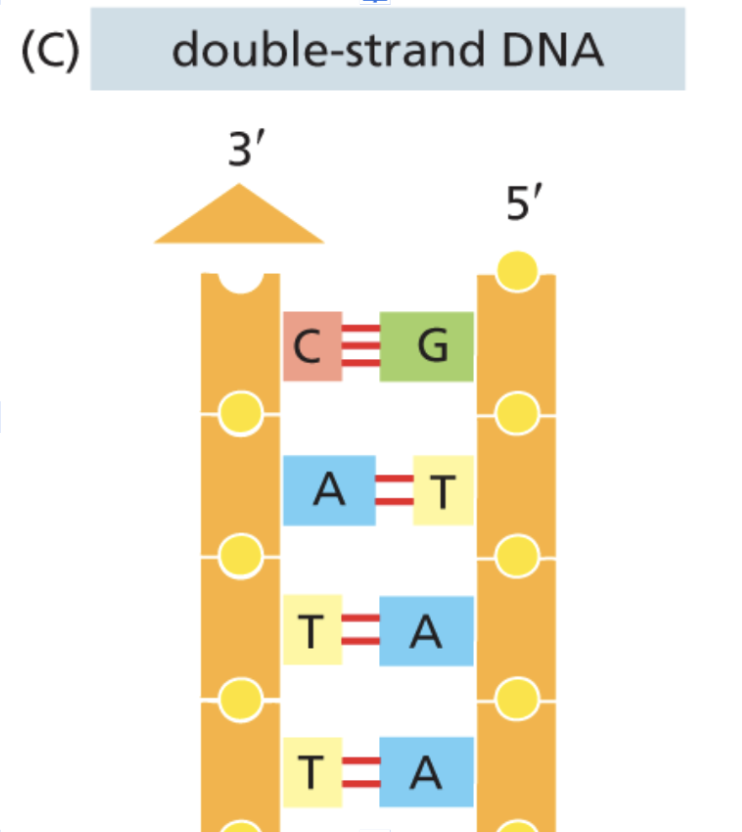
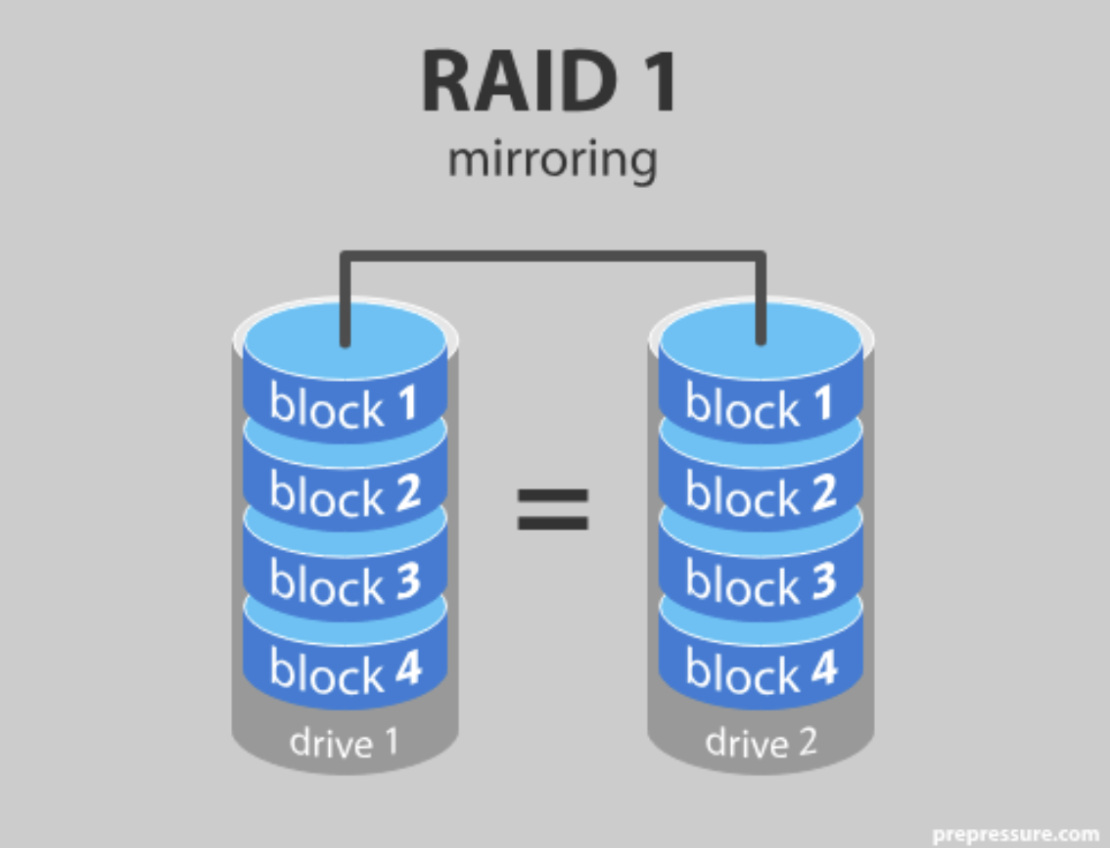
RAID and DNA's double-strandedness serve the same purpose: fault tolerance
Further analogs can be drawn between genomics and computing.
Inside the nucleus of the cell, DNA is transcribed into mRNA: the messenger of DNA’s data to ribosomes for protein production outside the nucleus. Before mRNA leaves the nucleus however, one end (5’) is capped and the other end (3’) is polyadenylated with several adenine (A) bases. With this mechanism in place, mRNA ends are protected from damage inside and outside the nucleus. Importantly, if the polyadenylation is corrupted, the mRNA molecule cannot be exported from the nucleus for protein production since export factors (i.e. proteins) in the nuclear membrane check for polyadenylation—just like a bouncer checking your ID at a bar. If this polyadenylation mechanism/check did not exist, mRNA molecules would be degraded upon exiting the nucleus and robust protein production would plummet.
In this sense, polyadenylation acts as a stack canary—the protection that CPU memory stacks have against buffer overflows in our computers. Stack canaries function as follows: when code is loaded into memory, a small, known value—a stack canary—is placed right before the return address of that code. If that code/return address gets corrupted (or maliciously exploited), the CPU will see that the stack canary is also modified—just like how the nuclear membrane sees that the polyadenylation of adenines (As) is corrupted—and will stop the program.
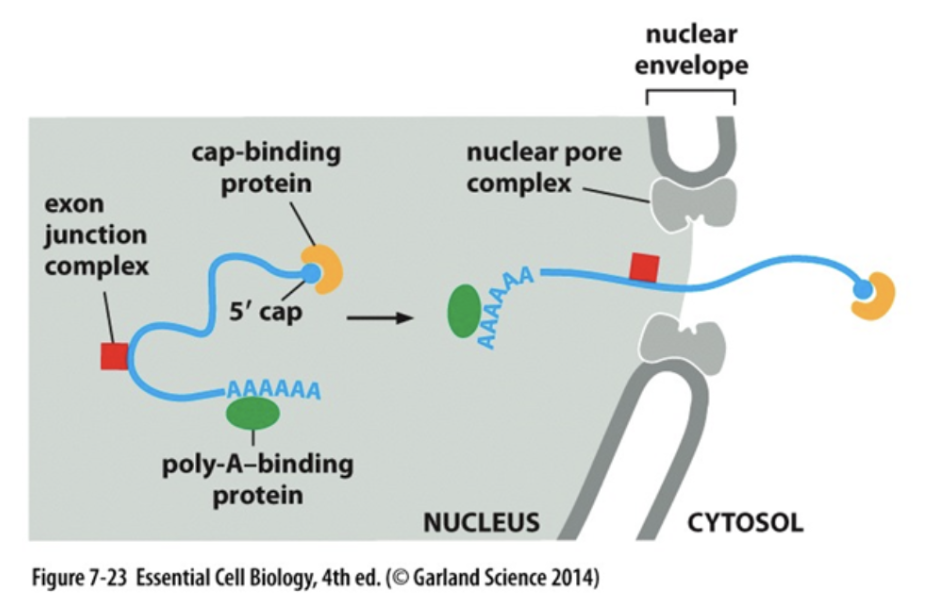
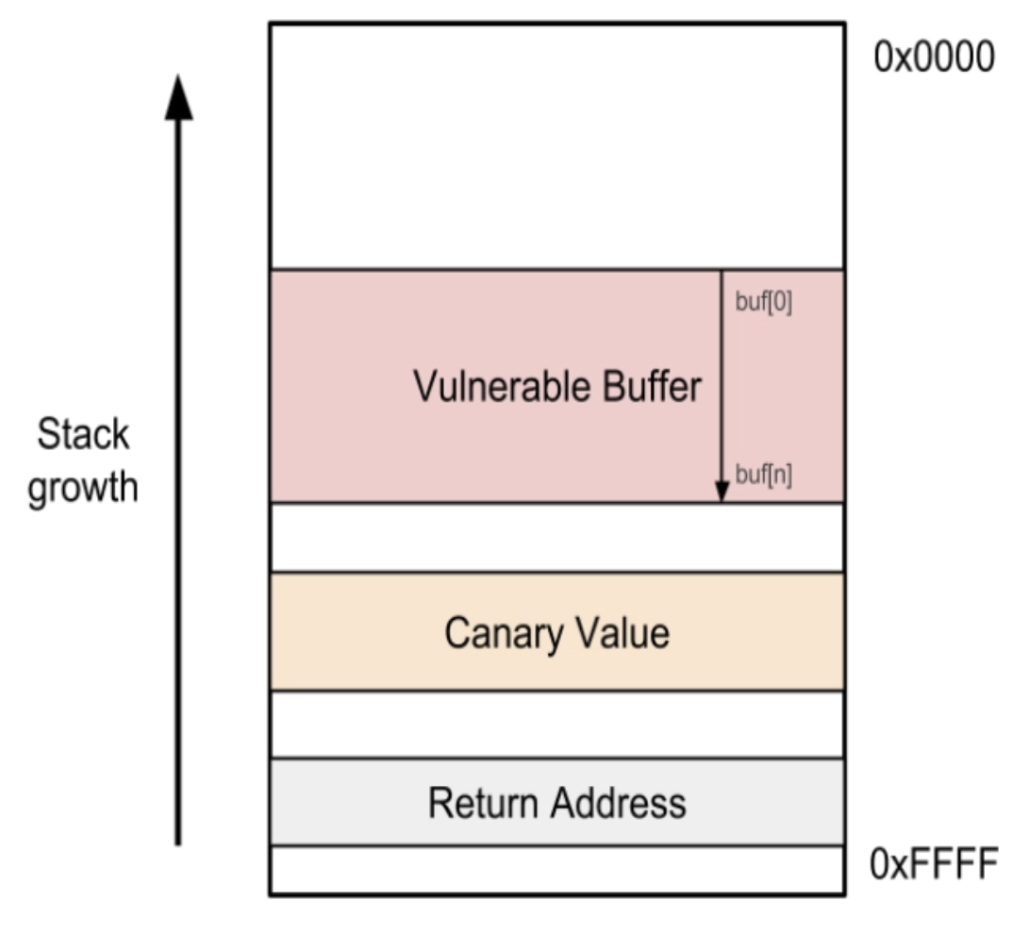
Stack canaries in memory and polyadenylations in mRNA both enhance the durability of their information systems by sacrificing bits of information
So far, I’ve given examples at the molecular level of the genetic information system—let’s zoom out a bit.
All cell types in humans have (nearly) the same DNA—so what makes lung cells different from neurons? There are a multitude of fascinating factors, but one I found particularly interesting was related to how DNA is organized in the nucleus.
Inside the nucleus, DNA is tightly coiled around proteins called histones, which form chromatin (which then form chromosomes). Interestingly, the degree to which DNA is wrapped around histones helps determine a gene’s expression level. If a gene is tightly wrapped, transcription machinery like RNA polymerase won’t bind to the gene and produce RNA. If loose, the gene is more exposed, and thus has a higher potential for expression. Different cells have varying levels of tightness at different spots in the genome, giving them different gene expressions and thus different functions.
What’s more interesting is that the DNA tightness around histones is inherited in child cells after cell division. This is part of what’s called epigenetic inheritance—it’s what makes sure lung cells stay lung cells and liver cells stay liver cells.
Reading about this really reminded me of the LLM fine-tuning technique LoRA, or low-rank adaptation. In LoRA, you freeze the core weights of the model and instead add low-rank weight matrices to act as deltas; these delta matrices are the outer-product of two thin matrices, thus making the matrix low-rank and the process parameter-efficient.
I see similarity in chromatin tightness and LoRA in a few ways. To begin, in both entities, the core underlying information—DNA or model weights—is frozen across all functional types (i.e. different cell types or different model versions). Second, both methods give you “efficient” means to produce dramatically different outputs from your information system. Lastly, both systems are quite modular; that is, one can swap in/out different LoRAs to get different finetuned models and one can change histone marks to program cells into other differentiated types (i.e. stem cell programming).
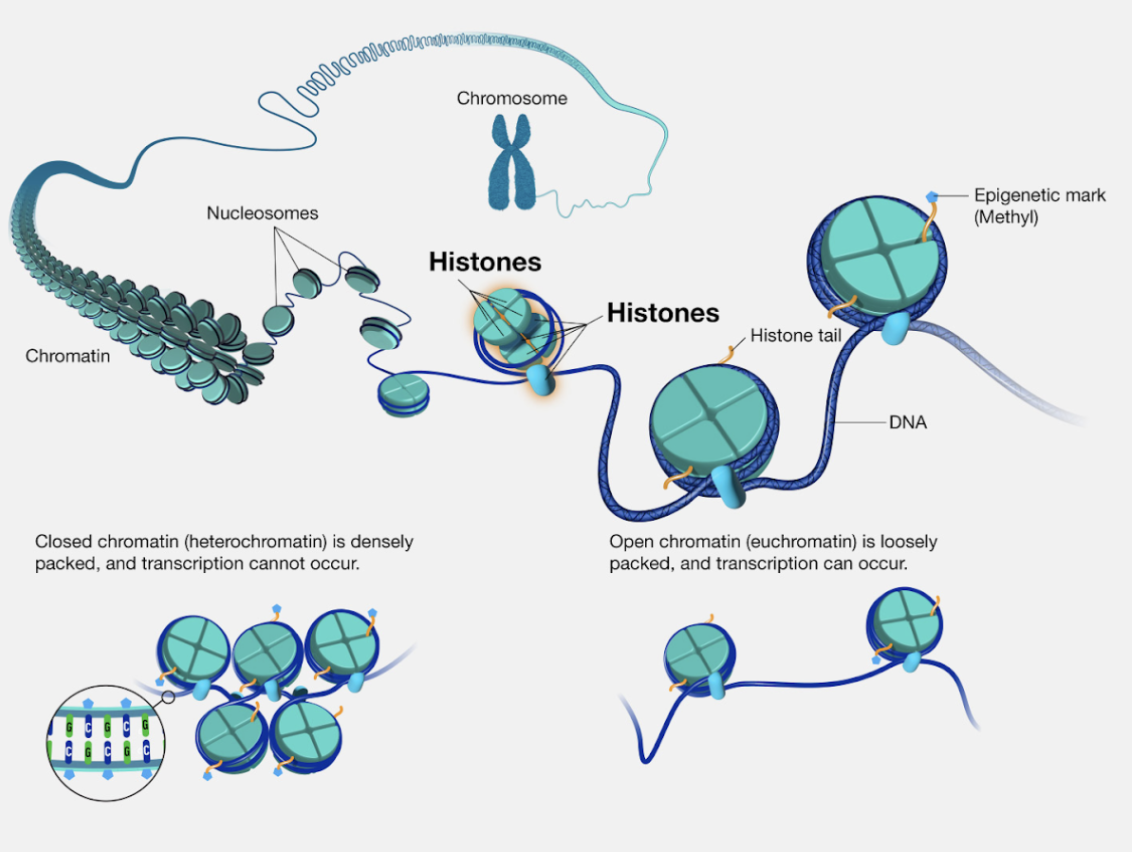
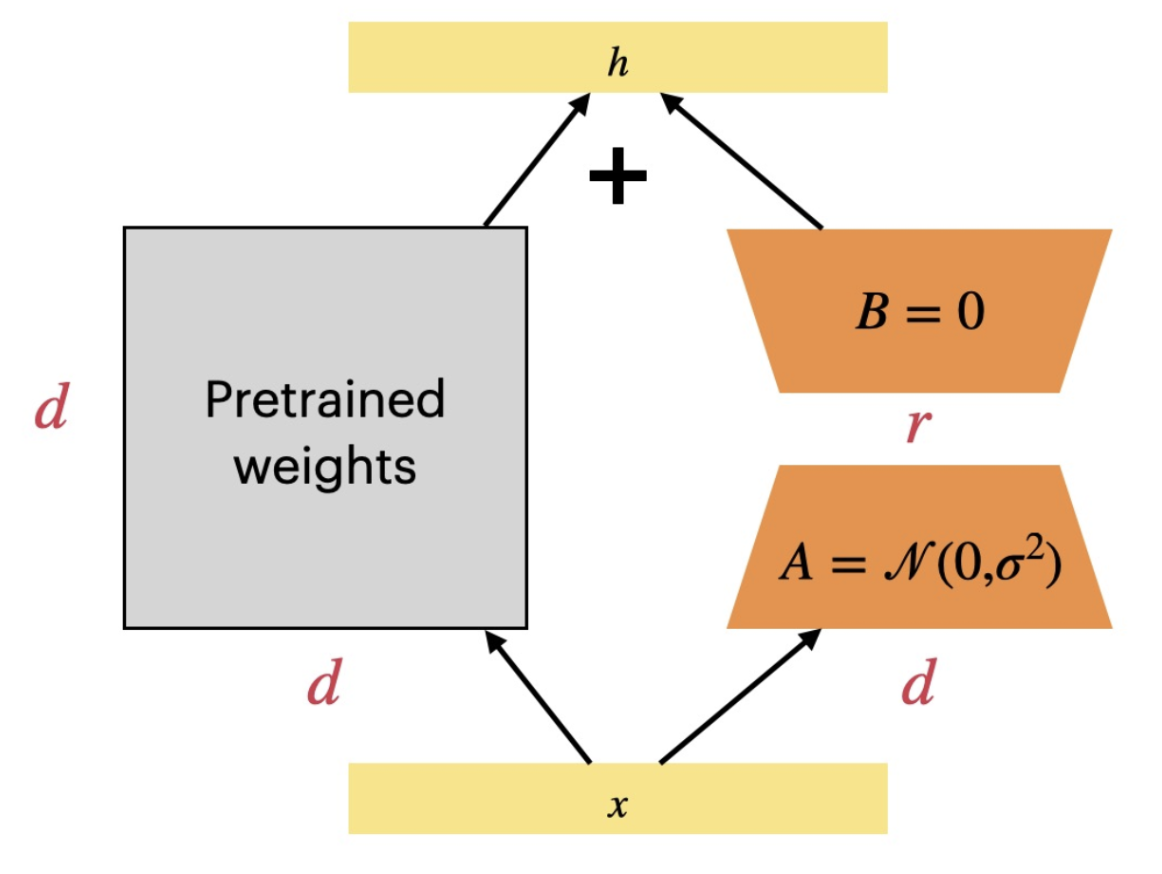
Chromatin tightness and LoRA both give their underlying systems extraordinary flexibility while keeping the core data unchanged
Of course, it can be argued that cells are a different class of information system than technology since their fault tolerance mechanisms fail much more often than technology's mechanisms do. After all, we are far more likely to develop a mutated phenotype such as cancer in old age than to see a SQL database crash decades after it was first deployed. That being said, biologists are working to supplement the cell's natural fault tolerance mechanisms with engineered ones. Arc Institute's recent work in programmable bridge recombinases is a wonderful example of this. More on that later.
The second key generalization I’d like to make is that cells are (incredibly complex) feedback control systems.
One of the key building blocks of this cellular feedback control system is the protein kinase, which essentially acts like a molecular switch. The protein kinase can be “turned on” by phosphorylation and “turned off” by dephosphorylation—which is essentially the addition/removal of a phosphate group on these proteins. When turned on, kinases can activate other kinases (thus triggering a cascade) or other target proteins (thus causing some end effect). Kinases can also be phosphorylated by multiple signals/kinases, giving them tremendous modularity. The flexibility of kinases gives rise to signaling pathways—similar to transistors with logic gates on a circuit board or even a neural network—like below:
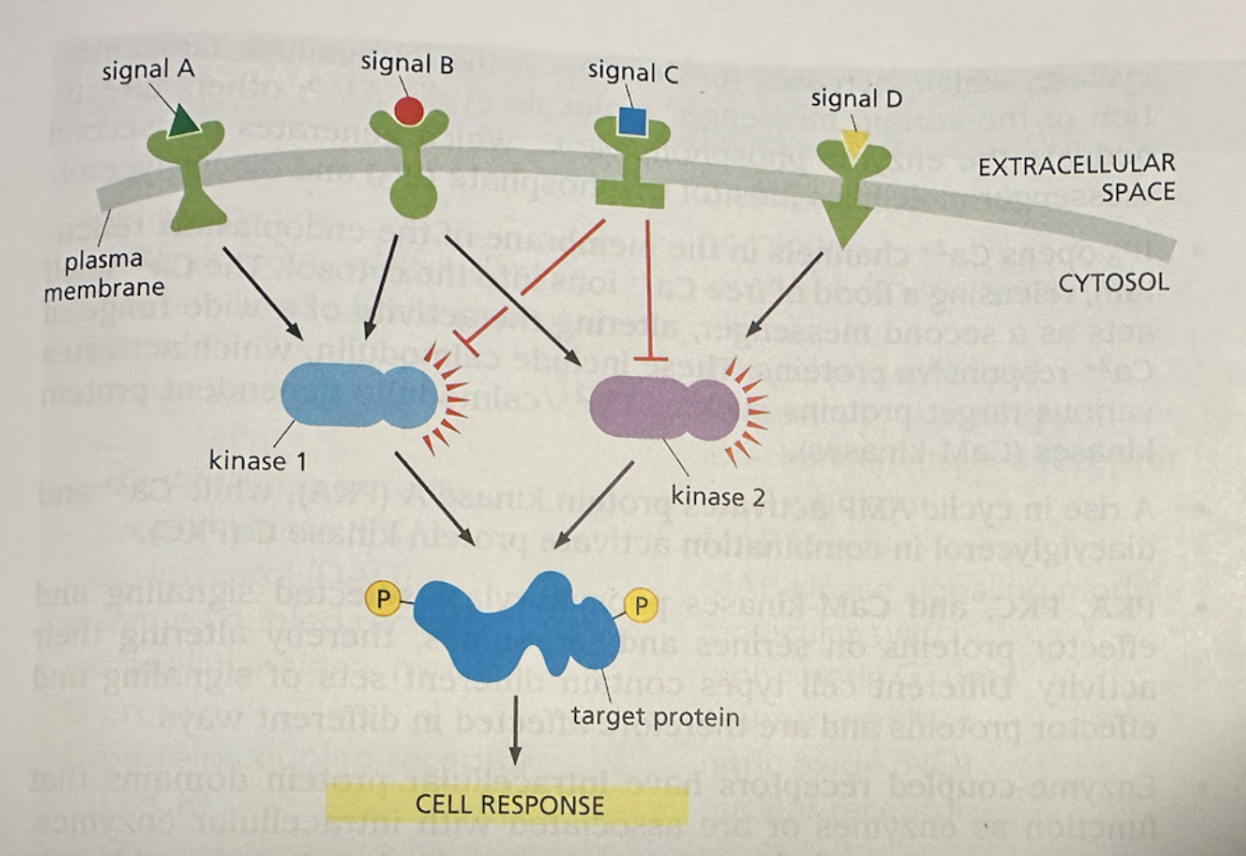
Kinases act as molecular switches for the cell's feedback control system
These simple, yet powerful building blocks give rise to much more complex feedback control systems, where cells have built in positive and negative feedback cycles—just like the self-driving software on your Tesla or Waymo. For example, in a self-driving car, adaptive cruise control is governed by feedback cycles. Sensors continuously measure the distance to the vehicle ahead; if the car drifts too close, braking is applied (negative feedback), and if the gap widens too much, acceleration is applied (positive adjustment). Similarly, lane-keeping systems use cameras and lidar to monitor the car’s position relative to lane markings. If the vehicle begins to drift, corrective steering inputs are applied to restore balance. These cycles of sensing, adjusting, and re-sensing mirror the way cells use kinases to regulate internal pathways—both systems rely on simple switches and cascades that scale into robust, adaptive feedback control.
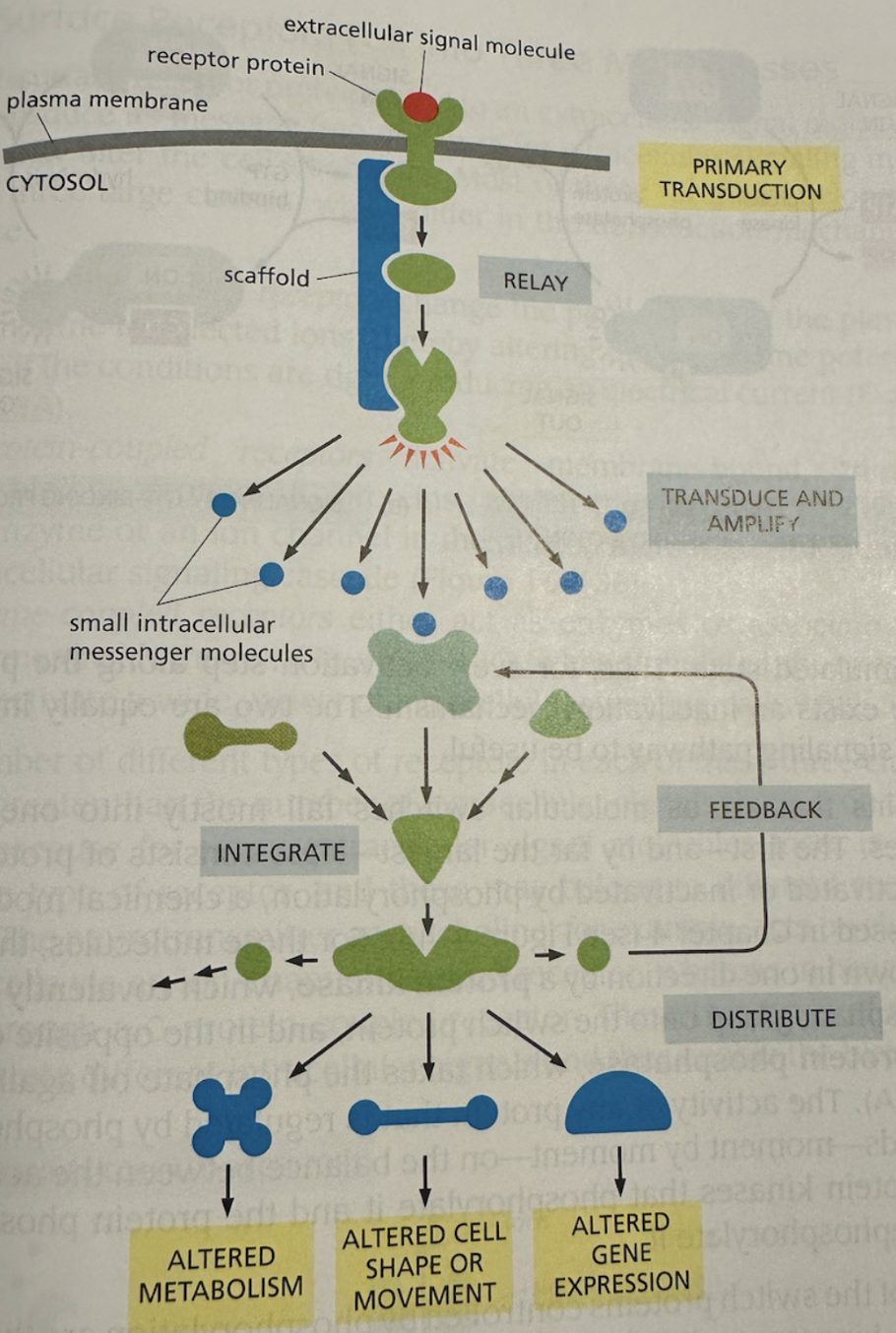

Cells are complex feedback control systems, just like the ones you see in today's advanced technologies
One of the coolest feedback control systems in the cell is the cell cycle—the process by which the cell divides and grows. The cell-cycle is quite complex; it features a plethora of different phases with clever checks at the end of each phase to determine if the cell is ready for the next phase or not. In fact, when I read about the cell cycle, it almost reads like the control flow you’d see in a complex backend API endpoint with if-statements and error handling.
STATE ∈ {G0,G1,S,G2,M,APOPTOSIS,SENESCENCE}
STATE := G1
signals := {mitogens:LOW|HIGH, nutrients:LOW|HIGH, DNA_damage:NONE|MILD|SEVERE, replication_stress:FALSE|TRUE, unattached_kinetochore:FALSE|TRUE}
levels := {CyclinD_CDK4_6:LOW, CyclinE_CDK2:LOW, CyclinA_CDK2:LOW, CyclinB_CDK1:LOW, p53:LOW, p21:LOW, Cdc25:INACTIVE, APC_Cdc20:INACTIVE, APC_Cdh1:INACTIVE}
licensing := {origins_loaded:FALSE, replication_complete:FALSE}
function SenseDamage():
if signals.DNA_damage != NONE:
levels.p53 := HIGH
levels.p21 := HIGH
levels.Cdc25 := INACTIVE
function TryRepair():
if signals.DNA_damage == MILD: signals.DNA_damage := NONE; return SUCCESS
if signals.DNA_damage == SEVERE: return FAILURE
return SUCCESS
function DecideFate():
if signals.DNA_damage == SEVERE: return APOPTOSIS
return SENESCENCE
function Transition_G1_to_S():
if signals.mitogens == HIGH and signals.nutrients == HIGH: levels.CyclinD_CDK4_6 := HIGH
SenseDamage()
if levels.p21 == HIGH: return BLOCKED
if levels.CyclinD_CDK4_6 == LOW: return BLOCKED
levels.CyclinE_CDK2 := HIGH
licensing.origins_loaded := TRUE
if levels.Cdc25 == INACTIVE: return BLOCKED
return ADVANCE
function Transition_S_to_G2():
levels.CyclinA_CDK2 := HIGH
if signals.replication_stress:
SenseDamage()
if TryRepair() == FAILURE: return FATE(DecideFate())
return BLOCKED
licensing.replication_complete := TRUE
return ADVANCE
function Transition_G2_to_M():
levels.CyclinB_CDK1 := HIGH
SenseDamage()
if levels.p21 == HIGH or levels.Cdc25 == INACTIVE:
if TryRepair() == FAILURE: return FATE(DecideFate())
return BLOCKED
levels.Cdc25 := ACTIVE
return ADVANCE
function Transition_M_to_G1():
if signals.unattached_kinetochore == TRUE:
levels.APC_Cdc20 := INACTIVE
return BLOCKED
levels.APC_Cdc20 := ACTIVE
levels.APC_Cdh1 := ACTIVE
levels.CyclinB_CDK1 := LOW
return ADVANCE
while TRUE:
switch STATE:
case G1:
if Transition_G1_to_S() == ADVANCE: STATE := S
else if signals.mitogens == LOW: STATE := G0
case G0:
if signals.mitogens == HIGH and signals.nutrients == HIGH: STATE := G1
case S:
t := Transition_S_to_G2()
if t == ADVANCE: STATE := G2
else if t is FATE(x): STATE := x
case G2:
t := Transition_G2_to_M()
if t == ADVANCE: STATE := M
else if t is FATE(x): STATE := x
case M:
if Transition_M_to_G1() == ADVANCE: STATE := G1
case APOPTOSIS: halt()
case SENESCENCE: idle_forever()
A (substantially) simplified cell-cycle control system
Given this observation that cells and modern technologies follow similar paradigms, one might next wonder “why do these two seemingly different things share such similarity?” I believe there are two digestible answers to this question. First, many technologies have gotten their inspiration from nature (e.g. neural networks are inspired by biological neurons). Second, capitalism induces artificial natural selection in technology. That is, technologies that are inefficient and ineffective will not last in the free market, similar to how evolution occurs via biological natural selection.
All in all, this is just the start of uncanny similarities between biology and technology. Some honorable mentions for cool concepts of biology I didn’t get to mention are cell membrane oligosaccharides and computer virus protection, ion channels and op amps, and microtubules and RL. At its core nevertheless, cells function much like modern technology: they store and transmit information while responding to signals in their environment.
A common hesitance to enter biology I hear from engineers is that “biology is all about memorization; software is about the creative application of first principles”. To be fair, this is somewhat true; I’ve just reached the tip of the iceberg in biology and I struggle to remember all the core concepts.
It’s critical to remember nonetheless that cells are information systems and feedback control systems—just like software. The implication of this is that these systems can be engineered to our liking—just like software.
Of course, bioengineering is much less straightforward than writing a few lines of code—or these days writing a prompt; we still don’t know many of the underlying principles of these biological information and feedback control systems and engineering them is expensive, unreliable, or downright impossible right now.
That being said, talented minds are working on these problems. I have had the privilege of working at the Liu Lab at UCSF for a couple months and now at Arc Institute, and I can confidently say that people are creatively hustling to accelerate biology and make it as seamless as software engineering.
I encourage any engineers reading this to try biology. The abstractions built in computing reappear in the cell: redundancy, error correction, feedback loops, modularity, and more. Once you start noticing them, it’s hard to unsee. The real challenge is to take this recognition further: to treat cells as information systems and feedback control systems that can be reasoned about, abstracted, and eventually engineered with the same confidence we bring to code. It won’t be as simple as pnpm-installing a library or writing a prompt, but the opportunity is exciting.
If you'd like to connect with me, feel free to email me here.